Synthetic Data Generation Software Market Size, Share & Trends Analysis Report by Component (Platforms/ Suites, APIs & SDKs, Toolkits/ Libraries, Simulators & Render Engines, Data Labeling & Annotation Modules, Monitoring & Quality Evaluation Tools, Professional Services and Others), Deployment Mode, Technology/ Technique, Model/ Data Type Supported, Enterprise Size, Data Modality, Integration/ Ecosystem, Application / Use Case, Industry Vertical and Geography (North America, Europe, Asia Pacific, Middle East, Africa, and South America) – Global Industry Data, Trends, and Forecasts, 2026–2035
|
Market Structure & Evolution |
|
|
Segmental Data Insights |
|
|
Demand Trends |
|
|
Competitive Landscape |
|
|
Strategic Development |
|
|
Future Outlook & Opportunities |
|
Synthetic Data Generation Software Market Size, Share, and Growth
The global synthetic data generation software market is experiencing robust growth, with its estimated value of USD 0.2 billion in the year 2025 and USD 8.2 billion by the period 2035, registering a CAGR of 44.1% during the forecast period. The synthetic data generation software market is growing quickly all over the world due to improvements in privacy-preserving AI, regulatory pressure, and the requirement for safe and scalable data for model training.

Jim Goodnight, SAS CEO, said, "Hazy's purchase of IP is a significant step forward in our commitment to innovation around the future of data management and AI. Hazy is setting the standard for a clean data solution as a readily available product for enterprises and is frequently ranked as one of the top vendors in this domain." Such a merger will be the source of privacy-respecting AI developments in highly regulated areas at a faster pace."
A significant change happened in November 2024 when SAS bought the synthetic-data intellectual property of Hazy, thus making it possible to embed enterprise-grade synthetic data capabilities in SAS’s analytics and AI platform - hence SAS is able to offer regulated users enhanced reliability, governance, and compliance.
The adoption of AI in the sectors of banking, insurance, and healthcare has escalated the need for high-quality synthetic datasets that remove personal identifiers and, at the same time, retain statistical fidelity. One such confirmed industry activity is Gretel.ai’s continued development of its privacy-preserving generative AI tools, which is a good indication of the market’s orientation towards on-demand data generation, automated balancing, and safe data augmentation for AI development.
Moreover, the tightening of the screws on regulation (e.g. GDPR, HIPAA, and global AI governance frameworks) has made organizations invest in synthetic data to lessen the risk of exposing sensitive data during analytics, model validation, and system testing. Hence, the coming together of factors such as technological innovation, compliance requirements, as well as enterprise AI scaling is resulting in strong growth of the synthetic data software market. Besides that, the worldwide synthetic data market is also a gateway to other sectors such as privacy-enhancing technologies (PETs), secure data collaboration platforms, AI model testing suites, data quality assessment tools, and domain-specific simulation engines.
Therefore, by capitalizing on these adjacencies, vendors can not only broaden the safety and compliance enterprise solutions but also raise the revenue possibilities that lie within the broader data ecosystem landscape.

Synthetic Data Generation Software Market Dynamics and Trends
Driver: Increasing Regulatory Pressure Driving Adoption of Synthetic Data Platforms
- The need for synthetic data generation software in the face of stringent global privacy and AI regulations, such as GDPR, HIPAA, the EU AI Act (2024), and NIST’s AI Risk Management Framework (2023), is the chief driver in this market expansion. All these regulations demand that AI/ML systems, which use PII, are provided with strict security measures. These standards leave organizations no other choice but to resort to privacy-preserving synthetic datasets, which are considered as compliant and safe substitutes for sensitive production data.
- The demand for secure data-sharing workflows has been raised additionally after recorded instances of fines imposed for illegal data processing under GDPR. As a result, banks, healthcare providers, and insurers are turning to synthetic data as a means of lessening their risk during analytics, testing, and model development.
- The indefinite digital transformation of the retail, finance, and public services sectors is leading to the need for sizable datasets that satisfy the privacy, data-retention, and sovereignty requirements without negatively impacting model performance.
Restraint: High Technical Complexity and Model Fidelity Challenges Slowing Broader Adoption
- While regulatory momentum has been quite strong, the adoption of enterprises is still limited due to the complexity of creating synthetic datasets that keep statistical fidelity, edge-case representation, and downstream model accuracy. A large number of organizations do not have the necessary expertise in generative modeling or data privacy engineering within their teams.
- Further, asynchronous synthetic data systems with old databases, data warehouses, and multi-cloud infrastructures require a considerable amount of money to be spent on pipeline orchestration, quality validation, and governance frameworks - especially for public sector institutions and traditional financial organizations.
- The necessity to review synthetic data in terms of privacy leakage, bias propagation, and utility performance is still causing the company to be in a state of operational overhead, thus limiting the number of small enterprises with a shortage of AI engineering resources that can take advantage of this technology.
Opportunity: Expansion Across Regulated Industries and Cross-Border Data Collaboration
- The use of data-localization rules in the EU, India, the Middle East, and Southeast Asia has significantly raised the demand for providers of artificial data. The reason is that companies are choosing artificial datasets for cross-border analytics without the actual need of transferring sensitive data to different authorities physically.
- Moreover, the healthcare, insurance, automotive, and financial services sectors are increasing the number of their pilots and production environments which use synthetic data for such use cases as testing, fraud modeling, drug discovery, and autonomous systems training. For example, Gretel.ai, Mostly AI, SAS, and MDClone are energetically working with big business to make sharing of data easy and compliant and to facilitate privacy-enhancing R&D.
- Governments and international organizations are turning to synthetic data for national statistical systems, census augmentation, and public-sector AI testing which in turn creates a need for vendors that provide privacy-respecting technologies certified by the authorities and government-grade compliance tools.
Key Trend: Integration of Generative AI, Privacy-Enhancing Technologies (PETs), and Automated Data Quality Pipelines
- The most recent wave of top-notch artificial data platforms are gradually adopting diffusion models, transformer-based tabular generators, and multimodal synthetic data engines that not only improve the data fidelity but also introduce privacy features such as differential privacy, k-anonymity, and membership-inference protection.
- Moreover, the mix of PETs like secure multi-party computation (SMPC), federated learning, homomorphic encryption, and confidential computing with synthetic data pipelines is what powers loka- scenario analytics to operate at zero risk of identity disclosure for financial institutions, pharma companies, and research organizations.
- Additionally, standardization efforts by ISO/IEC JTC 1 SC42 (AI), the EU’s AI Act technical guidance groups, and the U.S. NIST synthetic data evaluation initiatives are setting the standards for utility, governance, and risk scoring. Owing to which, this is paving the way for the implementation of automated data-quality validation engines that are effortlessly linked to synthetic data platforms.
Synthetic Data Generation Software Market Analysis and Segmental Data

“Platforms / Suites Lead Global Synthetic Data Generation Software Market amid Rising Demand for Integrated, End-to-End Privacy-Preserving Data Pipelines"
- Platforms-based artificial data suites, which incorporate generation, privacy risk scoring, data balancing, and utility testing in a single workflow, are being progressively used by enterprises in banking, insurance, and healthcare. As organizations move from one-off tools to integrated platforms that can fulfill regulatory and operational compliance requirements, companies like Gretel.ai, Mostly AI, SAS (via Hazy IP acquisition), and MDClone are experiencing a rapid uptake.
- The coupling of synthetic data engines with AI/ML SDKs and MLOps platforms opens the door to the automation of dataset generation, bias correction, and simulation workflows. Model-development pipelines in the enterprise can be seamlessly integrated through connectors for Databricks, Snowflake, AWS, and Python SDKs.
- Moreover, a number of regulatory frameworks such as the EU AI Act, NIST AI RMF, GDPR, and healthcare privacy laws are increasingly viewing synthetic data as a privacy-respecting asset that can be trusted; thus, they are steering governments and regulated industries towards platform-centric solutions.
- The rising generation of synthetic data platforms is equipped with features such as scalable APIs, real-time generation, and automated validation dashboards. The solutions from MDClone, Datagen, and Mostly AI serve as examples of how suite-based capabilities have evolved to be indispensable for secure analytics, compliant AI training, and cross-border data collaboration.
“North America Leads Synthetic Data Generation Software Market with Strong Regulatory Adoption, Advanced AI Infrastructure, and High Enterprise Privacy Demand"
- North America is the major player in the synthetic data generation software market with support from strict privacy laws, the rise of enterprise AI, and the great use of privacy-enhancing technologies. The regulatory anchors such as GDPR-based state privacy acts (CCPA/CPRA, Colorado Privacy Act, Virginia CDPA) and NIST’s AI Risk Management Framework (2023) have sped up the move to synthetic data as a compliant solution to sensitive production datasets.
- A number of leading technology firms-Microsoft, AWS, Google Cloud, NVIDIA, and Databricks-are equipping AI development environments with synthetic data functionalities that allow scalable model training, simulation, and data quality validation across financial services, healthcare, and public-sector applications. These collaborations allow enterprises to mitigate privacy risks while at the same time executing high-performance AI workloads.
- The Digital Governance Council (DGC) and the Standards Council of Canada (SCC) are leading initiatives in Canada that are paving the way for data governance standards and privacy-preserving analytics, thus enabling the creation of more secure data-sharing frameworks that use synthetic data as a base.
- The United States and Canada, with their quick AI adoption, strong cloud-native investments, and increased need for privacy-preserving data pipelines, are setting the global standards for compliant AI development and secure data collaboration, thus strengthening North America's leadership in the synthetic data generation software market.
Synthetic-Data-Generation-Software-Market Ecosystem
The synthetic data generation software market is highly consolidated and gradually centralizing around the top contributors like Gretel.ai, Mostly AI, Tonic.ai, Synthesis AI, Scale AI, and Rendered.ai, who are redefining the competition with their leading-edge generative-AI technologies and privacy solutions of enterprise grade. To this end, their products-such as domain-specific tabular generators, computer-vision simulation engines, and privacy-risk scoring modules-are enabling the creation of high-fidelity, regulation-compliant synthetic datasets for sensitive industries.
The pace of innovation in the field is being set by government agencies and research institutions. A major milestone was the acquisition of Hazy's synthetic-data intellectual property by SAS in November 2024 which resulted in easier enterprise access to privacy-preserving data generation capabilities and better compliance for the financial and healthcare sectors.
Such initiatives are in line with the continuous funding from standards bodies like NIST which published its AI Risk Management Framework in January 2023 emphasizing the importance of safe model-training data.
Leading vendors are looking to broaden the scope of their offerings through fully integrated pipelines that link data generation, validation, and deployment thereby enhancing operational efficiency and enabling the scaling of AI development. NVIDIA made a significant step forward in this area in March 2024 by accelerating synthetic data workflows with GPU-accelerated generative models, thus enabling faster data generation and improving model-training performance. Combined, these steps signal the market's robust drive for innovation, compliance, and the provision of enterprise-ready synthetic data solutions.

Recent Development and Strategic Overview:
- In November 2024, SAS expanded its synthetic data functionality by purchasing the intellectual property of Hazy, a leading enterprise synthetic data provider. As a result of this acquisition, SAS Viya platform now features the integration of Hazy’s state-of-the-art generative-modeling technology, which includes privacy-preserving tabular data engines and automated utility evaluation tools. The invention allowed enterprises to have broader access to compliant synthetic datasets for use in analytics, model validation, and risk modeling while enhancing privacy protection and regulatory compliance in the financial and healthcare sectors.
- In March 2024, NVIDIA took a significant step in the synthetic data ecosystem by upgrading GPU-accelerated workflows for generative AI through its Omniverse and AI Foundation models. The changes brought by these updates had the effect of speeding up the creation of high-quality synthetic datasets for computer vision and robotics by utilizing physically based rendering and diffusion-model architecture.
Report Scope
|
Attribute |
Detail |
|
Market Size in 2025 |
USD 0.2 Bn |
|
Market Forecast Value in 2035 |
USD 8.2 Bn |
|
Growth Rate (CAGR) |
44.1% |
|
Forecast Period |
2026 – 2035 |
|
Historical Data Available for |
2021 – 2024 |
|
Market Size Units |
USD Bn for Value |
|
Report Format |
Electronic (PDF) + Excel |
|
Regions and Countries Covered |
|||||
|
North America |
Europe |
Asia Pacific |
Middle East |
Africa |
South America |
|
|
|
|
|
|
|
Companies Covered |
|||||
|
|
|
|
|
|
Synthetic-Data-Generation-Software-Market Segmentation and Highlights
|
Segment |
Sub-segment |
|
Synthetic Data Generation Software Market, By Component |
|
|
Synthetic Data Generation Software Market, By Deployment Mode |
|
|
Synthetic Data Generation Software Market, By Technology/ Technique |
|
|
Synthetic Data Generation Software Market, By Model/ Data Type Supported |
|
|
Synthetic Data Generation Software Market, By Enterprise Size |
|
|
Synthetic Data Generation Software Market, By Data Modality |
|
|
Synthetic Data Generation Software Market, By Integration/ Ecosystem |
|
|
Synthetic Data Generation Software Market, By Application / Use Case |
|
|
Synthetic Data Generation Software Market, By Industry Vertical |
|
Frequently Asked Questions
Table of Contents
- 1. Research Methodology and Assumptions
- 1.1. Definitions
- 1.2. Research Design and Approach
- 1.3. Data Collection Methods
- 1.4. Base Estimates and Calculations
- 1.5. Forecasting Models
- 1.5.1. Key Forecast Factors & Impact Analysis
- 1.6. Secondary Research
- 1.6.1. Open Sources
- 1.6.2. Paid Databases
- 1.6.3. Associations
- 1.7. Primary Research
- 1.7.1. Primary Sources
- 1.7.2. Primary Interviews with Stakeholders across Ecosystem
- 2. Executive Summary
- 2.1. Global Synthetic Data Generation Software Market Outlook
- 2.1.1. Synthetic Data Generation Software Market Size (Value - US$ Bn), and Forecasts, 2021-2035
- 2.1.2. Compounded Annual Growth Rate Analysis
- 2.1.3. Growth Opportunity Analysis
- 2.1.4. Segmental Share Analysis
- 2.1.5. Geographical Share Analysis
- 2.2. Market Analysis and Facts
- 2.3. Supply-Demand Analysis
- 2.4. Competitive Benchmarking
- 2.5. Go-to- Market Strategy
- 2.5.1. Customer/ End-use Industry Assessment
- 2.5.2. Growth Opportunity Data, 2026-2035
- 2.5.2.1. Regional Data
- 2.5.2.2. Country Data
- 2.5.2.3. Segmental Data
- 2.5.3. Identification of Potential Market Spaces
- 2.5.4. GAP Analysis
- 2.5.5. Potential Attractive Price Points
- 2.5.6. Prevailing Market Risks & Challenges
- 2.5.7. Preferred Sales & Marketing Strategies
- 2.5.8. Key Recommendations and Analysis
- 2.5.9. A Way Forward
- 2.1. Global Synthetic Data Generation Software Market Outlook
- 3. Industry Data and Premium Insights
- 3.1. Global Information Technology & Media Ecosystem Overview, 2025
- 3.1.1. Information Technology & Media Industry Analysis
- 3.1.2. Key Trends for Information Technology & Media Industry
- 3.1.3. Regional Distribution for Information Technology & Media Industry
- 3.2. Supplier Customer Data
- 3.3. Technology Roadmap and Developments
- 3.1. Global Information Technology & Media Ecosystem Overview, 2025
- 4. Market Overview
- 4.1. Market Dynamics
- 4.1.1. Drivers
- 4.1.1.1. Rising demand for privacy-preserving data for AI model training and testing
- 4.1.1.2. Growing adoption of synthetic data solutions across healthcare, finance, and technology sectors
- 4.1.1.3. Increasing regulatory requirements for data privacy, security, and compliance (e.g., GDPR, CCPA, HIPAA)
- 4.1.2. Restraints
- 4.1.2.1. High implementation and integration costs of synthetic data generation software
- 4.1.2.2. Challenges in achieving high-fidelity synthetic data and integrating with legacy AI workflows
- 4.1.1. Drivers
- 4.2. Key Trend Analysis
- 4.3. Regulatory Framework
- 4.3.1. Key Regulations, Norms, and Subsidies, by Key Countries
- 4.3.2. Tariffs and Standards
- 4.3.3. Impact Analysis of Regulations on the Market
- 4.4. Value Chain Analysis
- 4.4.1. Data Suppliers
- 4.4.2. System Integrators
- 4.4.3. Synthetic Data Generation Software Providers
- 4.4.4. End Users
- 4.5. Cost Structure Analysis
- 4.5.1. Parameter’s Share for Cost Associated
- 4.5.2. COGP vs COGS
- 4.5.3. Profit Margin Analysis
- 4.6. Pricing Analysis
- 4.6.1. Regional Pricing Analysis
- 4.6.2. Segmental Pricing Trends
- 4.6.3. Factors Influencing Pricing
- 4.7. Porter’s Five Forces Analysis
- 4.8. PESTEL Analysis
- 4.9. Global Synthetic Data Generation Software Market Demand
- 4.9.1. Historical Market Size –Value (US$ Bn), 2020-2024
- 4.9.2. Current and Future Market Size –Value (US$ Bn), 2026–2035
- 4.9.2.1. Y-o-Y Growth Trends
- 4.9.2.2. Absolute $ Opportunity Assessment
- 4.1. Market Dynamics
- 5. Competition Landscape
- 5.1. Competition structure
- 5.1.1. Fragmented v/s consolidated
- 5.2. Company Share Analysis, 2025
- 5.2.1. Global Company Market Share
- 5.2.2. By Region
- 5.2.2.1. North America
- 5.2.2.2. Europe
- 5.2.2.3. Asia Pacific
- 5.2.2.4. Middle East
- 5.2.2.5. Africa
- 5.2.2.6. South America
- 5.3. Product Comparison Matrix
- 5.3.1. Specifications
- 5.3.2. Market Positioning
- 5.3.3. Pricing
- 5.1. Competition structure
- 6. Global Synthetic Data Generation Software Market Analysis, by Component
- 6.1. Key Segment Analysis
- 6.2. Synthetic Data Generation Software Market Size (Value - US$ Bn), Analysis, and Forecasts, by Component, 2021-2035
- 6.2.1. Platforms / Suites
- 6.2.2. APIs & SDKs
- 6.2.3. Toolkits / Libraries
- 6.2.4. Simulators & Render Engines
- 6.2.5. Data Labeling & Annotation Modules
- 6.2.6. Monitoring & Quality Evaluation Tools
- 6.2.7. Professional Services
- 6.2.8. Others
- 7. Global Synthetic Data Generation Software Market Analysis, by Deployment Mode
- 7.1. Key Segment Analysis
- 7.2. Synthetic Data Generation Software Market Size (Value - US$ Bn), Analysis, and Forecasts, by Deployment Mode, 2021-2035
- 7.2.1. Cloud-Based
- 7.2.2. On-Premises
- 7.2.3. Hybrid
- 8. Global Synthetic Data Generation Software Market Analysis, by Technology/ Technique
- 8.1. Key Segment Analysis
- 8.2. Synthetic Data Generation Software Market Size (Value - US$ Bn), Analysis, and Forecasts, by Technology/ Technique, 2021-2035
- 8.2.1. Generative Adversarial Networks (GANs)
- 8.2.2. Variational Autoencoders (VAEs)
- 8.2.3. Diffusion Models
- 8.2.4. Simulation-based Rendering (photorealistic engines)
- 8.2.5. Rule-based / Procedural Generation
- 8.2.6. Domain Randomization
- 8.2.7. Hybrid (sim-to-real + ML augmentation)
- 8.2.8. Others
- 9. Global Synthetic Data Generation Software Market Analysis, by Model/ Data Type Supported
- 9.1. Key Segment Analysis
- 9.2. Synthetic Data Generation Software Market Size (Value - US$ Bn), Analysis, and Forecasts, by Model/ Data Type Supported, 2021-2035
- 9.2.1. Text / LLM Governance
- 9.2.2. Computer Vision Model Governance
- 9.2.3. Tabular / Structured Model Governance
- 9.2.4. Multimodal Model Governance
- 9.2.5. Streaming / Real-time Data Models
- 9.2.6. Others
- 10. Global Synthetic Data Generation Software Market Analysis, by Enterprise Size
- 10.1. Key Segment Analysis
- 10.2. Synthetic Data Generation Software Market Size (Value - US$ Bn), Analysis, and Forecasts, by Enterprise Size, 2021-2035
- 10.2.1. Large Enterprises
- 10.2.2. Small & Medium Enterprises (SMEs)
- 10.2.3. Public Sector / Government Agencies
- 11. Global Synthetic Data Generation Software Market Analysis, by Data Modality
- 11.1. Key Segment Analysis
- 11.2. Synthetic Data Generation Software Market Size (Value - US$ Bn), Analysis, and Forecasts, by Data Modality, 2021-2035
- 11.2.1. Image (2D)
- 11.2.2. Video (Temporal / Synthetic sequences)
- 11.2.3. 3D / Point Cloud / LiDAR
- 11.2.4. Text / Natural Language
- 11.2.5. Structured / Tabular Data
- 11.2.6. Time-series / Sensor Data
- 11.2.7. Audio / Speech
- 11.2.8. Others
- 12. Global Synthetic Data Generation Software Market Analysis, by Integration/ Ecosystem
- 12.1. Key Segment Analysis
- 12.2. Synthetic Data Generation Software Market Size (Value - US$ Bn), Analysis, and Forecasts, by Integration/ Ecosystem, 2021-2035
- 12.2.1. MLOps / CI-CD Pipeline Integration
- 12.2.2. Simulation Engine Integrations (Unity, Unreal, Omniverse)
- 12.2.3. Cloud ML Service Integrations (SageMaker, Vertex AI, Azure ML)
- 12.2.4. Data Lake / Data Warehouse Connectors
- 12.2.5. Others
- 13. Global Synthetic Data Generation Software Market Analysis, by Application / Use Case
- 13.1. Key Segment Analysis
- 13.2. Synthetic Data Generation Software Market Size (Value - US$ Bn), Analysis, and Forecasts, by Application / Use Case, 2021-2035
- 13.2.1. Computer Vision Model Training (detection, segmentation)
- 13.2.2. Autonomous Vehicle Perception & Simulation
- 13.2.3. Robotics Perception & Control
- 13.2.4. Medical Imaging & Healthcare Data Augmentation
- 13.2.5. Finance / Synthetic Transaction Data for ML
- 13.2.6. NLP Training & Privacy-preserving Text Data
- 13.2.7. AR/VR Content & Game Asset Generation
- 13.2.8. Cybersecurity / Log-simulation for SOC testing
- 13.2.9. Others
- 14. Global Synthetic Data Generation Software Market Analysis, by Industry Vertical
- 14.1. Key Segment Analysis
- 14.2. Synthetic Data Generation Software Market Size (Value - US$ Bn), Analysis, and Forecasts, by Industry Vertical, 2021-2035
- 14.2.1. Automotive & Transportation
- 14.2.2. Healthcare & Life Sciences
- 14.2.3. Retail & E-commerce
- 14.2.4. Media, Entertainment & Gaming
- 14.2.5. BFSI (Banking, Financial Services & Insurance)
- 14.2.6. Telecom & IoT
- 14.2.7. Manufacturing & Industrial Automation
- 14.2.8. Government & Defense
- 14.2.9. Others
- 15. Global Synthetic Data Generation Software Market Analysis and Forecasts, by Region
- 15.1. Key Findings
- 15.2. Synthetic Data Generation Software Market Size (Value - US$ Bn), Analysis, and Forecasts, by Region, 2021-2035
- 15.2.1. North America
- 15.2.2. Europe
- 15.2.3. Asia Pacific
- 15.2.4. Middle East
- 15.2.5. Africa
- 15.2.6. South America
- 16. North America Synthetic Data Generation Software Market Analysis
- 16.1. Key Segment Analysis
- 16.2. Regional Snapshot
- 16.3. North America Synthetic Data Generation Software Market Size Value - US$ Bn), Analysis, and Forecasts, 2021-2035
- 16.3.1. Component
- 16.3.2. Deployment Mode
- 16.3.3. Technology/ Technique
- 16.3.4. Model/ Data Type Supported
- 16.3.5. Enterprise Size
- 16.3.6. Data Modality
- 16.3.7. Integration/ Ecosystem
- 16.3.8. Application / Use Case
- 16.3.9. Industry Vertical
- 16.3.10. Country
- 16.3.10.1. USA
- 16.3.10.2. Canada
- 16.3.10.3. Mexico
- 16.4. USA Synthetic Data Generation Software Market
- 16.4.1. Country Segmental Analysis
- 16.4.2. Component
- 16.4.3. Deployment Mode
- 16.4.4. Technology/ Technique
- 16.4.5. Model/ Data Type Supported
- 16.4.6. Enterprise Size
- 16.4.7. Data Modality
- 16.4.8. Integration/ Ecosystem
- 16.4.9. Application / Use Case
- 16.4.10. Industry Vertical
- 16.5. Canada Synthetic Data Generation Software Market
- 16.5.1. Country Segmental Analysis
- 16.5.2. Component
- 16.5.3. Deployment Mode
- 16.5.4. Technology/ Technique
- 16.5.5. Model/ Data Type Supported
- 16.5.6. Enterprise Size
- 16.5.7. Data Modality
- 16.5.8. Integration/ Ecosystem
- 16.5.9. Application / Use Case
- 16.5.10. Industry Vertical
- 16.6. Mexico Synthetic Data Generation Software Market
- 16.6.1. Country Segmental Analysis
- 16.6.2. Component
- 16.6.3. Deployment Mode
- 16.6.4. Technology/ Technique
- 16.6.5. Model/ Data Type Supported
- 16.6.6. Enterprise Size
- 16.6.7. Data Modality
- 16.6.8. Integration/ Ecosystem
- 16.6.9. Application / Use Case
- 16.6.10. Industry Vertical
- 17. Europe Synthetic Data Generation Software Market Analysis
- 17.1. Key Segment Analysis
- 17.2. Regional Snapshot
- 17.3. Europe Synthetic Data Generation Software Market Size (Value - US$ Bn), Analysis, and Forecasts, 2021-2035
- 17.3.1. Component
- 17.3.2. Deployment Mode
- 17.3.3. Technology/ Technique
- 17.3.4. Model/ Data Type Supported
- 17.3.5. Enterprise Size
- 17.3.6. Data Modality
- 17.3.7. Integration/ Ecosystem
- 17.3.8. Application / Use Case
- 17.3.9. Industry Vertical
- 17.3.10. Country
- 17.3.10.1. Germany
- 17.3.10.2. United Kingdom
- 17.3.10.3. France
- 17.3.10.4. Italy
- 17.3.10.5. Spain
- 17.3.10.6. Netherlands
- 17.3.10.7. Nordic Countries
- 17.3.10.8. Poland
- 17.3.10.9. Russia & CIS
- 17.3.10.10. Rest of Europe
- 17.4. Germany Synthetic Data Generation Software Market
- 17.4.1. Country Segmental Analysis
- 17.4.2. Component
- 17.4.3. Deployment Mode
- 17.4.4. Technology/ Technique
- 17.4.5. Model/ Data Type Supported
- 17.4.6. Enterprise Size
- 17.4.7. Data Modality
- 17.4.8. Integration/ Ecosystem
- 17.4.9. Application / Use Case
- 17.4.10. Industry Vertical
- 17.5. United Kingdom Synthetic Data Generation Software Market
- 17.5.1. Country Segmental Analysis
- 17.5.2. Component
- 17.5.3. Deployment Mode
- 17.5.4. Technology/ Technique
- 17.5.5. Model/ Data Type Supported
- 17.5.6. Enterprise Size
- 17.5.7. Data Modality
- 17.5.8. Integration/ Ecosystem
- 17.5.9. Application / Use Case
- 17.5.10. Industry Vertical
- 17.6. France Synthetic Data Generation Software Market
- 17.6.1. Country Segmental Analysis
- 17.6.2. Component
- 17.6.3. Deployment Mode
- 17.6.4. Technology/ Technique
- 17.6.5. Model/ Data Type Supported
- 17.6.6. Enterprise Size
- 17.6.7. Data Modality
- 17.6.8. Integration/ Ecosystem
- 17.6.9. Application / Use Case
- 17.6.10. Industry Vertical
- 17.7. Italy Synthetic Data Generation Software Market
- 17.7.1. Country Segmental Analysis
- 17.7.2. Component
- 17.7.3. Deployment Mode
- 17.7.4. Technology/ Technique
- 17.7.5. Model/ Data Type Supported
- 17.7.6. Enterprise Size
- 17.7.7. Data Modality
- 17.7.8. Integration/ Ecosystem
- 17.7.9. Application / Use Case
- 17.7.10. Industry Vertical
- 17.8. Spain Synthetic Data Generation Software Market
- 17.8.1. Country Segmental Analysis
- 17.8.2. Component
- 17.8.3. Deployment Mode
- 17.8.4. Technology/ Technique
- 17.8.5. Model/ Data Type Supported
- 17.8.6. Enterprise Size
- 17.8.7. Data Modality
- 17.8.8. Integration/ Ecosystem
- 17.8.9. Application / Use Case
- 17.8.10. Industry Vertical
- 17.9. Netherlands Synthetic Data Generation Software Market
- 17.9.1. Country Segmental Analysis
- 17.9.2. Component
- 17.9.3. Deployment Mode
- 17.9.4. Technology/ Technique
- 17.9.5. Model/ Data Type Supported
- 17.9.6. Enterprise Size
- 17.9.7. Data Modality
- 17.9.8. Integration/ Ecosystem
- 17.9.9. Application / Use Case
- 17.9.10. Industry Vertical
- 17.10. Nordic Countries Synthetic Data Generation Software Market
- 17.10.1. Country Segmental Analysis
- 17.10.2. Component
- 17.10.3. Deployment Mode
- 17.10.4. Technology/ Technique
- 17.10.5. Model/ Data Type Supported
- 17.10.6. Enterprise Size
- 17.10.7. Data Modality
- 17.10.8. Integration/ Ecosystem
- 17.10.9. Application / Use Case
- 17.10.10. Industry Vertical
- 17.11. Poland Synthetic Data Generation Software Market
- 17.11.1. Country Segmental Analysis
- 17.11.2. Component
- 17.11.3. Deployment Mode
- 17.11.4. Technology/ Technique
- 17.11.5. Model/ Data Type Supported
- 17.11.6. Enterprise Size
- 17.11.7. Data Modality
- 17.11.8. Integration/ Ecosystem
- 17.11.9. Application / Use Case
- 17.11.10. Industry Vertical
- 17.12. Russia & CIS Synthetic Data Generation Software Market
- 17.12.1. Country Segmental Analysis
- 17.12.2. Component
- 17.12.3. Deployment Mode
- 17.12.4. Technology/ Technique
- 17.12.5. Model/ Data Type Supported
- 17.12.6. Enterprise Size
- 17.12.7. Data Modality
- 17.12.8. Integration/ Ecosystem
- 17.12.9. Application / Use Case
- 17.12.10. Industry Vertical
- 17.13. Rest of Europe Synthetic Data Generation Software Market
- 17.13.1. Country Segmental Analysis
- 17.13.2. Component
- 17.13.3. Deployment Mode
- 17.13.4. Technology/ Technique
- 17.13.5. Model/ Data Type Supported
- 17.13.6. Enterprise Size
- 17.13.7. Data Modality
- 17.13.8. Integration/ Ecosystem
- 17.13.9. Application / Use Case
- 17.13.10. Industry Vertical
- 18. Asia Pacific Synthetic Data Generation Software Market Analysis
- 18.1. Key Segment Analysis
- 18.2. Regional Snapshot
- 18.3. Asia Pacific Synthetic Data Generation Software Market Size (Value - US$ Bn), Analysis, and Forecasts, 2021-2035
- 18.3.1. Component
- 18.3.2. Deployment Mode
- 18.3.3. Technology/ Technique
- 18.3.4. Model/ Data Type Supported
- 18.3.5. Enterprise Size
- 18.3.6. Data Modality
- 18.3.7. Integration/ Ecosystem
- 18.3.8. Application / Use Case
- 18.3.9. Industry Vertical
- 18.3.10. Country
- 18.3.10.1. China
- 18.3.10.2. India
- 18.3.10.3. Japan
- 18.3.10.4. South Korea
- 18.3.10.5. Australia and New Zealand
- 18.3.10.6. Indonesia
- 18.3.10.7. Malaysia
- 18.3.10.8. Thailand
- 18.3.10.9. Vietnam
- 18.3.10.10. Rest of Asia Pacific
- 18.4. China Synthetic Data Generation Software Market
- 18.4.1. Country Segmental Analysis
- 18.4.2. Component
- 18.4.3. Deployment Mode
- 18.4.4. Technology/ Technique
- 18.4.5. Model/ Data Type Supported
- 18.4.6. Enterprise Size
- 18.4.7. Data Modality
- 18.4.8. Integration/ Ecosystem
- 18.4.9. Application / Use Case
- 18.4.10. Industry Vertical
- 18.5. India Synthetic Data Generation Software Market
- 18.5.1. Country Segmental Analysis
- 18.5.2. Component
- 18.5.3. Deployment Mode
- 18.5.4. Technology/ Technique
- 18.5.5. Model/ Data Type Supported
- 18.5.6. Enterprise Size
- 18.5.7. Data Modality
- 18.5.8. Integration/ Ecosystem
- 18.5.9. Application / Use Case
- 18.5.10. Industry Vertical
- 18.6. Japan Synthetic Data Generation Software Market
- 18.6.1. Country Segmental Analysis
- 18.6.2. Component
- 18.6.3. Deployment Mode
- 18.6.4. Technology/ Technique
- 18.6.5. Model/ Data Type Supported
- 18.6.6. Enterprise Size
- 18.6.7. Data Modality
- 18.6.8. Integration/ Ecosystem
- 18.6.9. Application / Use Case
- 18.6.10. Industry Vertical
- 18.7. South Korea Synthetic Data Generation Software Market
- 18.7.1. Country Segmental Analysis
- 18.7.2. Component
- 18.7.3. Deployment Mode
- 18.7.4. Technology/ Technique
- 18.7.5. Model/ Data Type Supported
- 18.7.6. Enterprise Size
- 18.7.7. Data Modality
- 18.7.8. Integration/ Ecosystem
- 18.7.9. Application / Use Case
- 18.7.10. Industry Vertical
- 18.8. Australia and New Zealand Synthetic Data Generation Software Market
- 18.8.1. Country Segmental Analysis
- 18.8.2. Component
- 18.8.3. Deployment Mode
- 18.8.4. Technology/ Technique
- 18.8.5. Model/ Data Type Supported
- 18.8.6. Enterprise Size
- 18.8.7. Data Modality
- 18.8.8. Integration/ Ecosystem
- 18.8.9. Application / Use Case
- 18.8.10. Industry Vertical
- 18.9. Indonesia Synthetic Data Generation Software Market
- 18.9.1. Country Segmental Analysis
- 18.9.2. Component
- 18.9.3. Deployment Mode
- 18.9.4. Technology/ Technique
- 18.9.5. Model/ Data Type Supported
- 18.9.6. Enterprise Size
- 18.9.7. Data Modality
- 18.9.8. Integration/ Ecosystem
- 18.9.9. Application / Use Case
- 18.9.10. Industry Vertical
- 18.10. Malaysia Synthetic Data Generation Software Market
- 18.10.1. Country Segmental Analysis
- 18.10.2. Component
- 18.10.3. Deployment Mode
- 18.10.4. Technology/ Technique
- 18.10.5. Model/ Data Type Supported
- 18.10.6. Enterprise Size
- 18.10.7. Data Modality
- 18.10.8. Integration/ Ecosystem
- 18.10.9. Application / Use Case
- 18.10.10. Industry Vertical
- 18.11. Thailand Synthetic Data Generation Software Market
- 18.11.1. Country Segmental Analysis
- 18.11.2. Component
- 18.11.3. Deployment Mode
- 18.11.4. Technology/ Technique
- 18.11.5. Model/ Data Type Supported
- 18.11.6. Enterprise Size
- 18.11.7. Data Modality
- 18.11.8. Integration/ Ecosystem
- 18.11.9. Application / Use Case
- 18.11.10. Industry Vertical
- 18.12. Vietnam Synthetic Data Generation Software Market
- 18.12.1. Country Segmental Analysis
- 18.12.2. Component
- 18.12.3. Deployment Mode
- 18.12.4. Technology/ Technique
- 18.12.5. Model/ Data Type Supported
- 18.12.6. Enterprise Size
- 18.12.7. Data Modality
- 18.12.8. Integration/ Ecosystem
- 18.12.9. Application / Use Case
- 18.12.10. Industry Vertical
- 18.13. Rest of Asia Pacific Synthetic Data Generation Software Market
- 18.13.1. Country Segmental Analysis
- 18.13.2. Component
- 18.13.3. Deployment Mode
- 18.13.4. Technology/ Technique
- 18.13.5. Model/ Data Type Supported
- 18.13.6. Enterprise Size
- 18.13.7. Data Modality
- 18.13.8. Integration/ Ecosystem
- 18.13.9. Application / Use Case
- 18.13.10. Industry Vertical
- 19. Middle East Synthetic Data Generation Software Market Analysis
- 19.1. Key Segment Analysis
- 19.2. Regional Snapshot
- 19.3. Middle East Synthetic Data Generation Software Market Size (Value - US$ Bn), Analysis, and Forecasts, 2021-2035
- 19.3.1. Component
- 19.3.2. Deployment Mode
- 19.3.3. Technology/ Technique
- 19.3.4. Model/ Data Type Supported
- 19.3.5. Enterprise Size
- 19.3.6. Data Modality
- 19.3.7. Integration/ Ecosystem
- 19.3.8. Application / Use Case
- 19.3.9. Industry Vertical
- 19.3.10. Country
- 19.3.10.1. Turkey
- 19.3.10.2. UAE
- 19.3.10.3. Saudi Arabia
- 19.3.10.4. Israel
- 19.3.10.5. Rest of Middle East
- 19.4. Turkey Synthetic Data Generation Software Market
- 19.4.1. Country Segmental Analysis
- 19.4.2. Component
- 19.4.3. Deployment Mode
- 19.4.4. Technology/ Technique
- 19.4.5. Model/ Data Type Supported
- 19.4.6. Enterprise Size
- 19.4.7. Data Modality
- 19.4.8. Integration/ Ecosystem
- 19.4.9. Application / Use Case
- 19.4.10. Industry Vertical
- 19.5. UAE Synthetic Data Generation Software Market
- 19.5.1. Country Segmental Analysis
- 19.5.2. Component
- 19.5.3. Deployment Mode
- 19.5.4. Technology/ Technique
- 19.5.5. Model/ Data Type Supported
- 19.5.6. Enterprise Size
- 19.5.7. Data Modality
- 19.5.8. Integration/ Ecosystem
- 19.5.9. Application / Use Case
- 19.5.10. Industry Vertical
- 19.6. Saudi Arabia Synthetic Data Generation Software Market
- 19.6.1. Country Segmental Analysis
- 19.6.2. Component
- 19.6.3. Deployment Mode
- 19.6.4. Technology/ Technique
- 19.6.5. Model/ Data Type Supported
- 19.6.6. Enterprise Size
- 19.6.7. Data Modality
- 19.6.8. Integration/ Ecosystem
- 19.6.9. Application / Use Case
- 19.6.10. Industry Vertical
- 19.7. Israel Synthetic Data Generation Software Market
- 19.7.1. Country Segmental Analysis
- 19.7.2. Component
- 19.7.3. Deployment Mode
- 19.7.4. Technology/ Technique
- 19.7.5. Model/ Data Type Supported
- 19.7.6. Enterprise Size
- 19.7.7. Data Modality
- 19.7.8. Integration/ Ecosystem
- 19.7.9. Application / Use Case
- 19.7.10. Industry Vertical
- 19.8. Rest of Middle East Synthetic Data Generation Software Market
- 19.8.1. Country Segmental Analysis
- 19.8.2. Component
- 19.8.3. Deployment Mode
- 19.8.4. Technology/ Technique
- 19.8.5. Model/ Data Type Supported
- 19.8.6. Enterprise Size
- 19.8.7. Data Modality
- 19.8.8. Integration/ Ecosystem
- 19.8.9. Application / Use Case
- 19.8.10. Industry Vertical
- 20. Africa Synthetic Data Generation Software Market Analysis
- 20.1. Key Segment Analysis
- 20.2. Regional Snapshot
- 20.3. Africa Synthetic Data Generation Software Market Size (Value - US$ Bn), Analysis, and Forecasts, 2021-2035
- 20.3.1. Component
- 20.3.2. Deployment Mode
- 20.3.3. Technology/ Technique
- 20.3.4. Model/ Data Type Supported
- 20.3.5. Enterprise Size
- 20.3.6. Data Modality
- 20.3.7. Integration/ Ecosystem
- 20.3.8. Application / Use Case
- 20.3.9. Industry Vertical
- 20.3.10. Country
- 20.3.10.1. South Africa
- 20.3.10.2. Egypt
- 20.3.10.3. Nigeria
- 20.3.10.4. Algeria
- 20.3.10.5. Rest of Africa
- 20.4. South Africa Synthetic Data Generation Software Market
- 20.4.1. Country Segmental Analysis
- 20.4.2. Component
- 20.4.3. Deployment Mode
- 20.4.4. Technology/ Technique
- 20.4.5. Model/ Data Type Supported
- 20.4.6. Enterprise Size
- 20.4.7. Data Modality
- 20.4.8. Integration/ Ecosystem
- 20.4.9. Application / Use Case
- 20.4.10. Industry Vertical
- 20.5. Egypt Synthetic Data Generation Software Market
- 20.5.1. Country Segmental Analysis
- 20.5.2. Component
- 20.5.3. Deployment Mode
- 20.5.4. Technology/ Technique
- 20.5.5. Model/ Data Type Supported
- 20.5.6. Enterprise Size
- 20.5.7. Data Modality
- 20.5.8. Integration/ Ecosystem
- 20.5.9. Application / Use Case
- 20.5.10. Industry Vertical
- 20.6. Nigeria Synthetic Data Generation Software Market
- 20.6.1. Country Segmental Analysis
- 20.6.2. Component
- 20.6.3. Deployment Mode
- 20.6.4. Technology/ Technique
- 20.6.5. Model/ Data Type Supported
- 20.6.6. Enterprise Size
- 20.6.7. Data Modality
- 20.6.8. Integration/ Ecosystem
- 20.6.9. Application / Use Case
- 20.6.10. Industry Vertical
- 20.7. Algeria Synthetic Data Generation Software Market
- 20.7.1. Country Segmental Analysis
- 20.7.2. Component
- 20.7.3. Deployment Mode
- 20.7.4. Technology/ Technique
- 20.7.5. Model/ Data Type Supported
- 20.7.6. Enterprise Size
- 20.7.7. Data Modality
- 20.7.8. Integration/ Ecosystem
- 20.7.9. Application / Use Case
- 20.7.10. Industry Vertical
- 20.8. Rest of Africa Synthetic Data Generation Software Market
- 20.8.1. Country Segmental Analysis
- 20.8.2. Component
- 20.8.3. Deployment Mode
- 20.8.4. Technology/ Technique
- 20.8.5. Model/ Data Type Supported
- 20.8.6. Enterprise Size
- 20.8.7. Data Modality
- 20.8.8. Integration/ Ecosystem
- 20.8.9. Application / Use Case
- 20.8.10. Industry Vertical
- 21. South America Synthetic Data Generation Software Market Analysis
- 21.1. Key Segment Analysis
- 21.2. Regional Snapshot
- 21.3. South America Synthetic Data Generation Software Market Size (Value - US$ Bn), Analysis, and Forecasts, 2021-2035
- 21.3.1. Component
- 21.3.2. Deployment Mode
- 21.3.3. Technology/ Technique
- 21.3.4. Model/ Data Type Supported
- 21.3.5. Enterprise Size
- 21.3.6. Data Modality
- 21.3.7. Integration/ Ecosystem
- 21.3.8. Application / Use Case
- 21.3.9. Industry Vertical
- 21.3.10. Country
- 21.3.10.1. Brazil
- 21.3.10.2. Argentina
- 21.3.10.3. Rest of South America
- 21.4. Brazil Synthetic Data Generation Software Market
- 21.4.1. Country Segmental Analysis
- 21.4.2. Component
- 21.4.3. Deployment Mode
- 21.4.4. Technology/ Technique
- 21.4.5. Model/ Data Type Supported
- 21.4.6. Enterprise Size
- 21.4.7. Data Modality
- 21.4.8. Integration/ Ecosystem
- 21.4.9. Application / Use Case
- 21.4.10. Industry Vertical
- 21.5. Argentina Synthetic Data Generation Software Market
- 21.5.1. Country Segmental Analysis
- 21.5.2. Component
- 21.5.3. Deployment Mode
- 21.5.4. Technology/ Technique
- 21.5.5. Model/ Data Type Supported
- 21.5.6. Enterprise Size
- 21.5.7. Data Modality
- 21.5.8. Integration/ Ecosystem
- 21.5.9. Application / Use Case
- 21.5.10. Industry Vertical
- 21.6. Rest of South America Synthetic Data Generation Software Market
- 21.6.1. Country Segmental Analysis
- 21.6.2. Component
- 21.6.3. Deployment Mode
- 21.6.4. Technology/ Technique
- 21.6.5. Model/ Data Type Supported
- 21.6.6. Enterprise Size
- 21.6.7. Data Modality
- 21.6.8. Integration/ Ecosystem
- 21.6.9. Application / Use Case
- 21.6.10. Industry Vertical
- 22. Key Players/ Company Profile
- 22.1. AI.Reverie
- 22.1.1. Company Details/ Overview
- 22.1.2. Company Financials
- 22.1.3. Key Customers and Competitors
- 22.1.4. Business/ Industry Portfolio
- 22.1.5. Product Portfolio/ Specification Details
- 22.1.6. Pricing Data
- 22.1.7. Strategic Overview
- 22.1.8. Recent Developments
- 22.2. Amazon Web Services, Inc.
- 22.3. Ansys, Inc.
- 22.4. Databricks, Inc.
- 22.5. Datagen
- 22.6. DataRobot, Inc.
- 22.7. Google LLC
- 22.8. Gretel.ai
- 22.9. Hazy
- 22.10. IBM Corporation
- 22.11. Microsoft Corporation
- 22.12. Mostly AI
- 22.13. NVIDIA Corporation
- 22.14. Parallel Domain
- 22.15. Rendered.ai
- 22.16. Scale AI, Inc.
- 22.17. Synthesis AI
- 22.18. Synthetaic
- 22.19. Tonic.ai
- 22.20. Unity Technologies
- 22.21. Others Key Players
- 22.1. AI.Reverie
Note* - This is just tentative list of players. While providing the report, we will cover more number of players based on their revenue and share for each geography
Research Design
Our research design integrates both demand-side and supply-side analysis through a balanced combination of primary and secondary research methodologies. By utilizing both bottom-up and top-down approaches alongside rigorous data triangulation methods, we deliver robust market intelligence that supports strategic decision-making.
MarketGenics' comprehensive research design framework ensures the delivery of accurate, reliable, and actionable market intelligence. Through the integration of multiple research approaches, rigorous validation processes, and expert analysis, we provide our clients with the insights needed to make informed strategic decisions and capitalize on market opportunities.
MarketGenics leverages a dedicated industry panel of experts and a comprehensive suite of paid databases to effectively collect, consolidate, and analyze market intelligence.
Our approach has consistently proven to be reliable and effective in generating accurate market insights, identifying key industry trends, and uncovering emerging business opportunities.
Through both primary and secondary research, we capture and analyze critical company-level data such as manufacturing footprints, including technical centers, R&D facilities, sales offices, and headquarters.
Our expert panel further enhances our ability to estimate market size for specific brands based on validated field-level intelligence.
Our data mining techniques incorporate both parametric and non-parametric methods, allowing for structured data collection, sorting, processing, and cleaning.
Demand projections are derived from large-scale data sets analyzed through proprietary algorithms, culminating in robust and reliable market sizing.
Research Approach
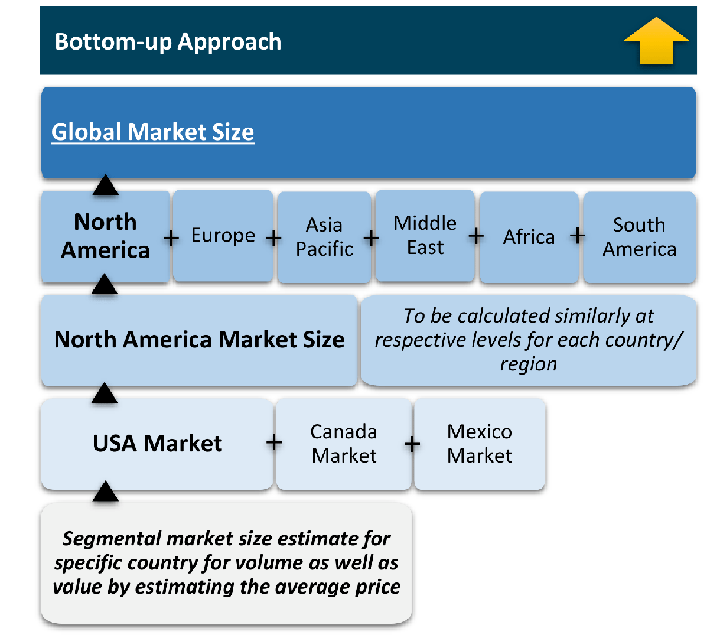
The bottom-up approach builds market estimates by starting with the smallest addressable market units and systematically aggregating them to create comprehensive market size projections.
This method begins with specific, granular data points and builds upward to create the complete market landscape.
Customer Analysis → Segmental Analysis → Geographical Analysis
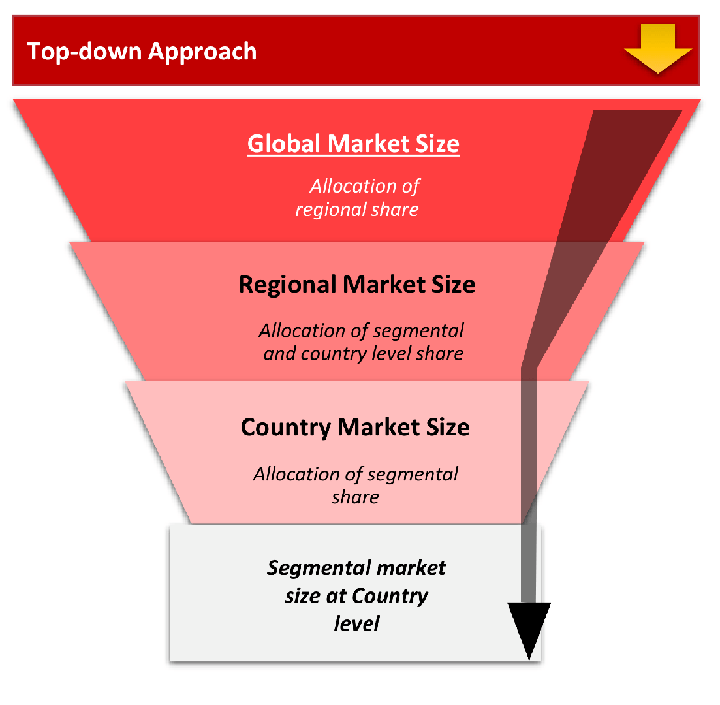
The top-down approach starts with the broadest possible market data and systematically narrows it down through a series of filters and assumptions to arrive at specific market segments or opportunities.
This method begins with the big picture and works downward to increasingly specific market slices.
TAM → SAM → SOM
Research Methods
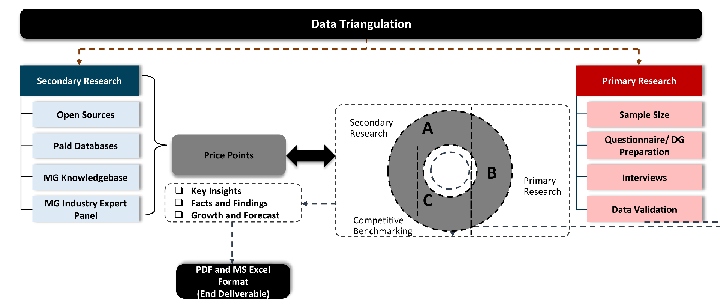
Desk / Secondary Research
While analysing the market, we extensively study secondary sources, directories, and databases to identify and collect information useful for this technical, market-oriented, and commercial report. Secondary sources that we utilize are not only the public sources, but it is a combination of Open Source, Associations, Paid Databases, MG Repository & Knowledgebase, and others.
- Company websites, annual reports, financial reports, broker reports, and investor presentations
- National government documents, statistical databases and reports
- News articles, press releases and web-casts specific to the companies operating in the market, Magazines, reports, and others
- We gather information from commercial data sources for deriving company specific data such as segmental revenue, share for geography, product revenue, and others
- Internal and external proprietary databases (industry-specific), relevant patent, and regulatory databases
- Governing Bodies, Government Organizations
- Relevant Authorities, Country-specific Associations for Industries
We also employ the model mapping approach to estimate the product level market data through the players' product portfolio
Primary Research
Primary research/ interviews is vital in analyzing the market. Most of the cases involves paid primary interviews. Primary sources include primary interviews through e-mail interactions, telephonic interviews, surveys as well as face-to-face interviews with the different stakeholders across the value chain including several industry experts.
| Type of Respondents | Number of Primaries |
|---|---|
| Tier 2/3 Suppliers | ~20 |
| Tier 1 Suppliers | ~25 |
| End-users | ~25 |
| Industry Expert/ Panel/ Consultant | ~30 |
| Total | ~100 |
MG Knowledgebase
• Repository of industry blog, newsletter and case studies
• Online platform covering detailed market reports, and company profiles
Forecasting Factors and Models
Forecasting Factors
- Historical Trends – Past market patterns, cycles, and major events that shaped how markets behave over time. Understanding past trends helps predict future behavior.
- Industry Factors – Specific characteristics of the industry like structure, regulations, and innovation cycles that affect market dynamics.
- Macroeconomic Factors – Economic conditions like GDP growth, inflation, and employment rates that affect how much money people have to spend.
- Demographic Factors – Population characteristics like age, income, and location that determine who can buy your product.
- Technology Factors – How quickly people adopt new technology and how much technology infrastructure exists.
- Regulatory Factors – Government rules, laws, and policies that can help or restrict market growth.
- Competitive Factors – Analyzing competition structure such as degree of competition and bargaining power of buyers and suppliers.
Forecasting Models / Techniques
Multiple Regression Analysis
- Identify and quantify factors that drive market changes
- Statistical modeling to establish relationships between market drivers and outcomes
Time Series Analysis – Seasonal Patterns
- Understand regular cyclical patterns in market demand
- Advanced statistical techniques to separate trend, seasonal, and irregular components
Time Series Analysis – Trend Analysis
- Identify underlying market growth patterns and momentum
- Statistical analysis of historical data to project future trends
Expert Opinion – Expert Interviews
- Gather deep industry insights and contextual understanding
- In-depth interviews with key industry stakeholders
Multi-Scenario Development
- Prepare for uncertainty by modeling different possible futures
- Creating optimistic, pessimistic, and most likely scenarios
Time Series Analysis – Moving Averages
- Sophisticated forecasting for complex time series data
- Auto-regressive integrated moving average models with seasonal components
Econometric Models
- Apply economic theory to market forecasting
- Sophisticated economic models that account for market interactions
Expert Opinion – Delphi Method
- Harness collective wisdom of industry experts
- Structured, multi-round expert consultation process
Monte Carlo Simulation
- Quantify uncertainty and probability distributions
- Thousands of simulations with varying input parameters
Research Analysis
Our research framework is built upon the fundamental principle of validating market intelligence from both demand and supply perspectives. This dual-sided approach ensures comprehensive market understanding and reduces the risk of single-source bias.
Demand-Side Analysis: We understand end-user/application behavior, preferences, and market needs along with the penetration of the product for specific application.
Supply-Side Analysis: We estimate overall market revenue, analyze the segmental share along with industry capacity, competitive landscape, and market structure.
Validation & Evaluation
Data triangulation is a validation technique that uses multiple methods, sources, or perspectives to examine the same research question, thereby increasing the credibility and reliability of research findings. In market research, triangulation serves as a quality assurance mechanism that helps identify and minimize bias, validate assumptions, and ensure accuracy in market estimates.
- Data Source Triangulation – Using multiple data sources to examine the same phenomenon
- Methodological Triangulation – Using multiple research methods to study the same research question
- Investigator Triangulation – Using multiple researchers or analysts to examine the same data
- Theoretical Triangulation – Using multiple theoretical perspectives to interpret the same data
Custom Market Research Services
We will customise the research for you, in case the report listed above does not meet your requirements.
Get 10% Free Customisation